728x90
맵과 리듀스
- 맵 리듀스는 맵 단계와 리듀스 단계로 구분되고, 각 단계는 입력과 출력을 키-값의 쌍을 가진다.
- 맵 단계의 입력은 원본 데이터이며 데이터셋의 각 행의 타입을 텍스트로 인식하는 텍스트 입력 포맷을 선택해야한다.
- 맵리듀스 시스템은 JobTracker, TaskTracker로 구성되고 master-slave 구조이다.
- 전체적인 맵 리듀스의 흐름은 다음과 같다.

Splitting(분할)
- 우선 대용량의 입력 파일을 split한후, 맵 함수를 적용한다.
- 대용량의 파일을 한꺼번에 처리할 수 없으므로 잘게 쪼개서 맵리듀스로 처리하는 방식이다.
Mapping(매핑)
- 분할된 데이터를 맵함수로 전달하고 맵함수는 해당 기준에 따라 문자 및 단어를 분리한다.
Shuffling(셔플링)
- Shuffling 단계에서 맵 함수의 결과를 합하고 리듀스 함수로 데이터를 전달하는 역할을 한다.
Reducing(리듀싱)
- 데이터 목록들을 반복적으로 수행하고 합을 계산한다.
JobTracker
- 맵 리듀스는 Job 이라고 하는 하나의 단위로 관리되고 소프트웨어 데몬에 의해 제어된다.
- Job Tracker는 하둡 클러스터에 있는 전체 Job의 스케줄링을 관리하며 모니터링한다.
- 전체 하둡 클러스터에서는 하나의 JobTracker가 구동되게 된다. 보통 Job Tracker는 네임 노드가 구동되는 서버에서 동작한다.
- 사용자가 맵리듀스 Job을 요청하게 되면 JobTracker는 몇 개의 맵과 리듀스를 실행하게 될 지를 계산한다.
- 이러한 task들을 어떤 TaskTracker에서 실행할 것인지를 결정하며, Task를 할당한다.
- JobTracker와 TaskTracker는 Heartbeats message를 사용하여 TaskTracker의 상태와 작업 실행 정보를 공유한다.
TaskTracker
- Task Tracker는 사용자가 설정한 맵리듀스 프로그램을 실행하며, 하둡의 데이터 노드에서 실행되는 데몬이다.
- JobTracker로부터 작업을 요청받으며, 그러면 map task와 reduce task를 생성하게 된다. 이러한 task가 생성되면 새로운 JVM을 구동해 task를 실행한다.
- 이 때 task를 실행하기 위한 JVM은 재사용될 수도 있다. 또한, 하나의 데이터 노드이더라도 여러 개의 JVM을 구동하여 데이터를 동시에 분산 처리하게 된다.
Mapper
- 각각의 입력 데이터의 일부를 처리하는 단계
- Key/Value의 쌍의 형태로 데이터를 읽는다.
- 입력은 Key/Value, 출력은 Key/Value list 형태이다.
Map 함수의 구현
// 최고 기온을 구하는 Mapper 함수의 예제
import java.io.IOEXception;
import org.apache.hadoop.io.IntWritable; // 필요한 패키지 정의
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class MaxTemperatureMapper
extends Mapper<LongWritable, Text, Text, IntWritable>{ // 입력 타입(입력키, 입력값, 출력키, 출력값)
private static final int MISSING = 9999; // 결측값은 9999로 대체
@Override
public void map(LongWritable key, Text value, Context context) // 하나의 키, 하나의 값 전달
throws IOException, InterruptedException{
String line = value.toString();
String year = line.substring(15,19); // 년도, 컬럼 추출을 위해 substring사용
int airTemperature;
if(line.charAt(87) == '+'){
airTemperature = Integer.parseInt(line.substring(88,92));
}
else{
airTemperature = Integer.parseInt(line.substring(87,92));
}
String quality = line.substring(92,93);
if(airTemperature != MISSING && quality.matches("[01459]")){
context.write(new Text(year), new IntWritable(airTemperature));
}
}
}
Reducer
- 맵 단계 이후, 리스트 형태로 조합된 값을 리듀서로 전달이 된다.
- Mapper와 마찬가지로 출력은 Key/Value쌍이어야 한다.
Reduce 함수의 구현
// 최고 기온을 구하는 Reducer 함수 예제
import java.io.IOException;
import org.apache.hadoop.io.IntWritable; // 필요한 패키지 정의
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class MaxTemperatureReducer
extends Reducer<Text, IntWritable, Text, IntWritable>{ // 출력 타입(Text, IntWritable)
@Override
public void reduce(Text key, Iterable<IntWritable> values, Context context)
throws IOException, InterruptedException{
int maxValue = Integer.MIN_VALUE; // 최고 기온
for(IntWritable value : values){
maxValue = Math.max(maxValue, value.get());
}
context.write(key, new IntWritable(maxValue));
}
}
// 리듀스 함수의 입력타입과 맵 함수의 출력타입은 짝을 이룸
// Text에는 연도를 IntWritable에는 해당 연도의 기온값을 모두 비교해 가장 높은 기온을 기록한다.
단일 리듀스 태스크
- 리듀스 태스크는 입력 크기와 상관없이 독립적으로 저장할 수 있다
- 리듀스가 여럿이면 맵 태스크는 리듀스 수만큼 파티션을 생성하고 맵의 결과를 각 파티션에 저장한다
- 각 파티션에는 여러 키가 존재하지만 개별 키에 속한 모든 레코드는 여러 파티션 중 한 곳에만 배치된다
- 모든 중간 데이터를 혼자 처리해야 되서 속도가 느리다는 단점이 있다
다수 리듀스 태스크
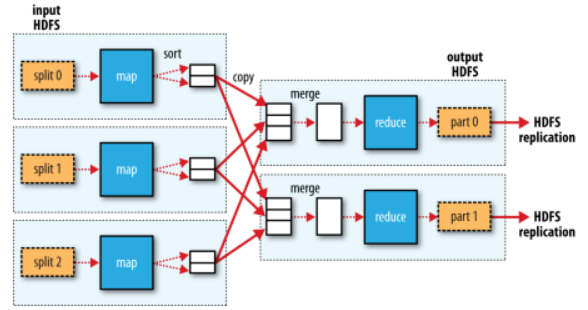
- 다수인 상황의 일반적인 데이터 흐름을 보여준다.
리듀스 태스크가 없는 경우
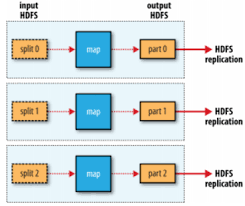
- 셔플이 필요 없고 모든 처리 과정을 완전히 병렬로 처리하는 경우에 적합하다
- 유일한 외부 노드 간의 데이터 전송은 맵 태스크가 결과를 HDFS에 저장할 때이다
출처:
'4학년 공부 과정 > 분산 데이터베이스' 카테고리의 다른 글
| 하둡(Hadoop) - NoSQL Database, HBase - 1 (2) | 2023.05.24 |
|---|---|
| 하둡(Hadoop) - 네임노드, 세컨더리 네임노드, 데이터노드 및 장애대응 (0) | 2023.04.28 |
| 하둡(Hadoop) - 하둡 분산 파일시스템(HDFS) (0) | 2023.03.12 |
| 하둡(Hadoop) 개요 (0) | 2023.03.11 |
| 하둡(Hadoop)에 관하여 (0) | 2023.03.11 |