728x90
HBase HMaster
- Region Server는 각 테이블의 데이터를 관리한다.
- HMaster
- 전체 클러스터를 관리하고 Region Server를 조정한다.
- Region Server 조정이란 로드 밸런싱을 위해서 Region을 재할당하거나 복구하는 일을 수행한다.
- 클러스터에 있는 모든 Region Server들을 주키퍼를 사용해 모니터링한다.
- 로드 밸런싱 : 서버가 처리해야 할 업무 혹은 요청(Load)을 여러 대의 서버로 나누어(Balancing) 처리하는 것을 의미한다.
- 너무 많은 로드 밸런싱도 문제가 발생할 수 있다(불균형의 문제 초래)

- 주키퍼를 이용해 클러스터 서버 상태를 관리하고 서비스들이 살아 있는지 사용 가능한지 모니터링 하고 실패 할 시 알림이 간다
- 클러스터간의 정보공유를 위한 저장소역할을 하며 보통 3대, 5대로 주키퍼 클러스터로 구성된다.
- Region Server, HMaster는 주키퍼에 연결되고 Heartbeat를 통해서 상태를 모니터링한다.
- 문제가 발생 시 클러스터에서 제외, HMaster가 실패할 경우 Master/Slave 방식으로 복제된 Inactive HMaster를 활성화한다.

HBase META 테이블
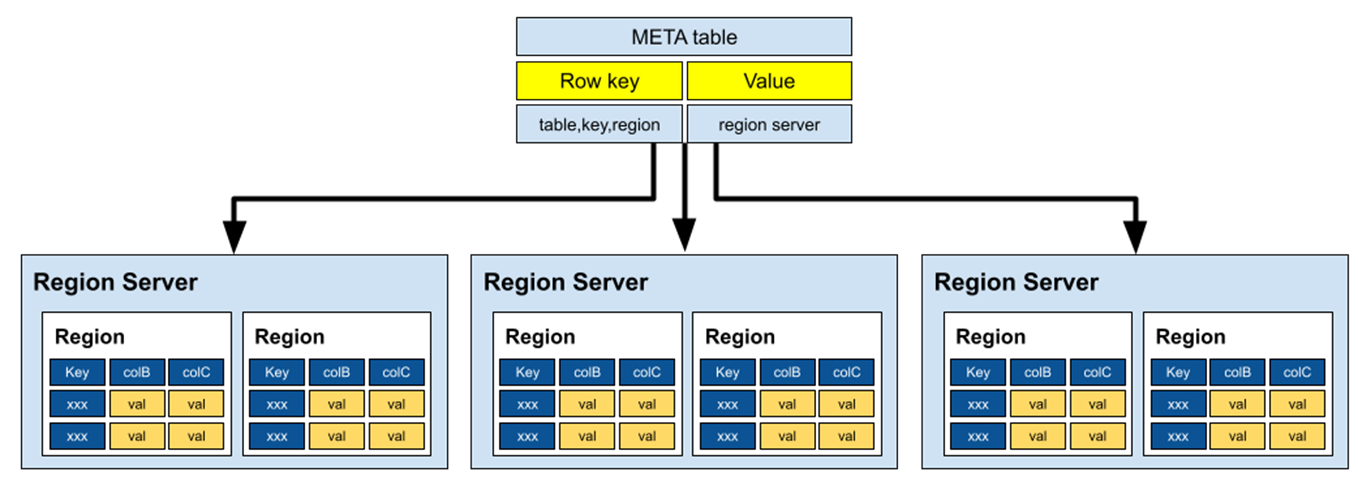
- META 테이블은 클러스터에 있는 모든 Region 정보를 저장한다.
- META 테이블의 구조는 Key-Value 쌍의 B-Tree형태로 구성된다.
- (Key, Value) => (Region ID 테이블, Region 서버)
HBase Region Server Component

- WAL : Write Ahead Log 파일로 HDFS에 기록되고, 모든 데이터는 영구이다.
- BlockCache : 읽기 캐시, 자주 접근하는 데이터를 메모리에 저장하여 읽기 성능을 향상시킨다.
- MemStore : 쓰기 캐시, 아직 디스크에 기록되지 않은 데이터를 저장한다.
- Hfile : Key-Value 형태로 데이터를 저장하는 파일
HBase 데이터 쓰기/읽기


쓰기 과정
- HBase에 데이터 적재 요청이 오면 먼저 적절한 Region Server을 찾게 된다.
- Region Server를 찾아 commit log를 추가 하고 메모리 내의 Memstore에 추가하게 된다.
- Memstore에 저장되어 있던 데이터는 설정되어 있는 설정값에 따라 가득차게 되면 HFile 형태로 디스크에 Flush되고 메모리를 비우고 다시 요청을 기다리게 되고 WAL 또한 이에 대한 기록을 하게 된다.
읽기 과정
- HBase에 요청이 들어오는 경우 먼저 Memstore를 살펴보게 되는데, Memstore에서 원하는 데이터를 찾으면 해당 데이터를 반환하게 된다.
- 그렇지 않은 경우 최근 Flush된 파일부터 오래된 순으로 쿼리를 만족하는 적합한 데이터를 발견하거나 더 이상 Flush 파일이 없을때까지 반복하게 된다.
HBase MemStore

- Key/Value 데이터를 정렬해서 저장하고, 이 데이터를 그대로 HFile에 저장한다.
- 하나의 컬럼 패밀리당 하나의 MemStore가 존재한다.
HBase Regin Flush

- Memstore에 충분한 데이터가 쌓이면, 정렬된 전체 집합을 HDFS에 새로운 HFile을 만들어서 저장한다.
- 컬럼패밀리가 늘어나면 HFile이 늘어나기 때문에, 컬럼 패밀리 수는 제한된다.
HBase Compaction

- Minor Compaction은 작은 HFile 파일들을 하나로 합치는 과정이다.
- 여러 개의 작은 HFile들이 생성되면 갯수가 많아지게 되어 데이터를 탐색하는 시간이 증가하여 성능이 저하될 수 있다.
- 여러 개의 HFile들이 병합하여 소수의 큰 HFiles로 생성함으로써 데이터 탐색 속도를 줄일 수 있다.
- minor compaction은 hbase.hstore.compaction.min / hbase.hstore.compaction.max 값으로 주기를 설정할 수 있다.
- hbase.hstore.compaction.min : minor compaction을 수행하기 위한 최소 StoreFile 수 기본값 3이다.
- hbase.hstore.compaction.max : minor compaction이 일어날 때, 처리하는 최대 StoreFile 갯수 기본값 10이다.

- Region에 있는 모든 HFile들을 병합해서 컬럼 패밀리 하나에 Hfile 하나 생성한다.
- 병합 과정에서 필요없는 셀, 시간이 초과된 셀 등을 제거하고 대량의 파일들에 대한 읽기/쓰기 작업이 일어나기 때문에 디스크 I/O와 트래픽 증가 발생한다.
- 서비스에 미치는 영향을 최소화하기 위해서 주말이나 야간으로 스케줄링이 가능하고 서버에 많은 부하가 생길 수 있어 자주 수행하는 것은 좋지 않다.
HBase Region Split

- 하나의 테이블은 하나의 Region에 저장된다.
- Region이 특정 크기 이상 커지면 Region을 두 개의 child Region으로 분할한다.
- Region을 나누어야 할 경우 이 정보를 HMaster에 보고하고, HMaster는 로드를 조정하기 위해서 새 Region을 다른 서버로 이동하기 위한 작업을 수행한다.
HBase Read Load Balancing

- Region split후 바로 HFile을 다른 노드로 이동하지 않는다.
- Region 서버만 다른 노드에 위치시키고 HFile의 물리적인 이동은 compaction 시에 수행한다.
HBase Crash Recovery
- 주키퍼는 Heart Beat 를 이용하여 Region 서버의 고장 여부 판단한다.
- Region Server가 고장이 나면 HMaster에 이를 통보하고 HMaster는 고장이 발생한 Region Server 의 Region을 다른 Region Server에 할당한다.
- 복제된 WAL 블록들을 이용하여 고장이 발생한 서버의 Memstore의 데이터 복구한다.
- 복제된 WAL 블록들을 분할하여 Region Server들에 복제해서 저장하고 각 Region서버는 데이터노드에 저장된 WAL 블록들을 이용하여 Memstore 복구한다.

'4학년 공부 과정 > 분산 데이터베이스' 카테고리의 다른 글
| 하둡(Hadoop) - Apache Kafka (2) | 2023.06.06 |
|---|---|
| 하둡(Hadoop) - 주키퍼(Zookeeper) (0) | 2023.05.31 |
| 하둡(Hadoop) - NoSQL Database, HBase - 1 (2) | 2023.05.24 |
| 하둡(Hadoop) - 네임노드, 세컨더리 네임노드, 데이터노드 및 장애대응 (0) | 2023.04.28 |
| 하둡(Hadoop) - 하둡 분산 파일시스템(HDFS) (0) | 2023.03.12 |