프로젝트를 수행하게 된 계기 :
2023년 6월 22일 제가 좋아하는 이세계아이돌의 새로운 노래 Lockdown이 나왔다 해서 스트리밍을 돌리던 와중 멜론 차트와 벅스 차트를 보던 도중 순위가 점점 올라가는 것을 보았습니다. 그걸 보면서 마침 방학인데 시간도 어느정도 있어서 프로젝트를 하나를 진행하면 좋다고 생각했습니다. 제가 자신있는 분야와 학교에서도 여러번 실행해보았던 워드클라우드, 감성, 장르 분류를 진행하게 되었습니다.
진행상황:
colab 환경에서 진행하였습니다.
우선 워드클라우드를 만들기 위한 패키지들을 모두 설치 해줍니다.
!pip install requests
!pip install BeautifulSoup4
우선 벅스 Top 100차트의 가사 기준으로 워드 클라우드를 만들었습니다. 차트의 데이터 기준은 6월 23일 밤 23시 기준으로 진행하였습니다.
크롤링을 하다 한가지 문제점이 있었는데 해당 url에서는 순위, 곡, 아티스트는 가져올 수 있었지만 가사는 해당 url과 다른 url에 존재하여 문제가 발생하였습니다.
import requests
from bs4 import BeautifulSoup
url = 'https://music.bugs.co.kr/chart'
request = requests.get(url)
html = request.text
soup = BeautifulSoup(html, 'html.parser')
titles = soup.select('p.title')
artists = soup.select('p.artist')
for i in range(len(titles)):
title = titles[i].text.strip().split('\n')[0]
artist = artists[i].text.strip().split('\n')[0]
print('{}위,{},{} '.format(i+1,title, artist))
그래서 확인을 해보니 가사는 곡 옆에 있는 아이콘을 눌러서 다른 url로 접속을 해야 가사를 볼 수 있는 형태였습니다.
해당 링크는 다음과 같은 형식으로 되어있습니다.
https://music.bugs.co.kr/track/6204236?wl_ref=list_tr_08_chart

다른곡의 가사들을 불러오는 방식은 제가 생각했던거와 마찬가지로 track 뒤에 있는 id값만 변경된다는 점을 알게 되어서 track_ids의 값들에 대한 배열을 만들어 id값은 따로 직접 입력하는 방식으로 크롤링을 진행하였습니다.
사실 이렇게 번거롭게 하지 않고 music.bugs.co.kr/chart에서 요소를 클릭하여 진행하는 방법도 있었지만 해당 css요소가 불명확할 뿐더러 인스타그램이나 페이스북 같은 경우는 크롤링 봇과 같은 요소를 감지할 수 있는 보안 요소가 있었던 것을 감안해서 이 방법은 사용하지 않았습니다.
# top 100
import csv
import requests
from bs4 import BeautifulSoup
def get_lyrics(lyrics_url):
request = requests.get(lyrics_url)
html = request.content
soup = BeautifulSoup(html, 'html.parser')
lyrics_element = soup.find('xmp') # xmp에 존재
lyrics = lyrics_element.text.strip()
return lyrics.replace('\n', '')
# 곡의 아이디
track_ids = ['6199292', '6195812', '6197839','32845387','6197837','6194446','6170217','32784610',
'6196923','6184997','6197215','4669063','6173112','6195057','6155092',
'32845389','6198716','6186207','6170060','6189185','32822499',
'6176123','98493924','6179181','6155955','6189316','95808160',
'103259794','31650949','101784672','6198616','88065250','32466413',
'6167302','6190714','32799067','6136060','32845388','32731774',
'3387407','6150789','6176179','103542404','6147666','6202761','6160273',
'6196273','31501137','81510510','6203591','6110464','6197256','6172716','6158327',
'6199216','32868889','6201910','6200268','6197962','32714302','32557292','31999479',
'6179174','76991868','6187548','32784611','30994623','6202756','6197674','6158753'
,'6171084','6201103','6190452','32636447','6167930','6131070','6202691','6140459'
,'32494898','6176266','6202691','6140459','32494898','6176266','6203050','6195597',
'94486995','32732271','32558931','6203861','6177182','6166336','6132120','6203792',
'6189186','6083049','103468731','6200029','6154437','6204009','32735024','6198891','6157002'] # 100개
# 차트 데이터
chart_data = []
for i, track_id in enumerate(track_ids):
lyrics_url = 'https://music.bugs.co.kr/track/{}'.format(track_id)
lyrics = get_lyrics(lyrics_url)
chart_data.append([i+1, lyrics])
# csv 파일로 전환
filename = 'dance_pop_lyrics.csv'
with open(filename, 'w', newline='', encoding='utf-8-sig') as file:
writer = csv.writer(file)
writer.writerow(['Rank','Lyrics'])
writer.writerows(chart_data)
print('{} 생성'.format(filename))
데이터를 수집을 한 뒤 데이터를 불러와 확인하는 작업을 했습니다.
우선 시각화를 할 떄 colab은 기본적으로 한글 폰트를 설치해야 되기 때문에 다음과 같은 코드를 입력하고 실행시켜줍니다.
# 폰트 설치
!sudo apt-get install -y fonts-nanum
!sudo fc-cache -fv
!rm ~/.cache/matplotlib -rf# 폰트 확인
import matplotlib.pyplot as plt
plt.rc('font', family='NanumBarunGothic')이후 파일을 불러와 제대로 저장이 되어있는지 확인을 합니다.
# 2023-06-23 23:00 기준 순위
import pandas as pd
data = pd.read_csv('/content/sample_data/music_chart_0623_1128.csv', encoding='cp949')
data하지만 제가 저장한 파일에는 단어 사이사이마다 \r와 같은 필요없는 값이 들어가 있었기에 필요없는 단어를 설정해주는
불용어 설정을 했습니다.
불용어 같은 경우는 nltk 패키지에 안에 있는 stopwords를 이용하였습니다.
# 불용어 설정으로 정제(원본 데이터)
import nltk
from nltk.corpus import stopwords
import pandas as pd
data = pd.read_csv('/content/sample_data/music_chart_0623_1128.csv', encoding='cp949')
# 불용어 설정
nltk.download('stopwords')
stop_words = set(stopwords.words('english'))
stop_words.add('\r')
# 불용어 제거 함수 정의
def remove_stopwords(text):
words = text.split()
filtered_words = [word for word in words if word.lower() not in stop_words]
return ' '.join(filtered_words)
# Lyrics 열에 불용어 제거 적용
data['Lyrics'] = data['Lyrics'].apply(remove_stopwords)
# 결과 확인
data
# csv파일로 변경
result_filename = 'music_chart_0623_1128.csv'
data.to_csv(result_filename, index=False, encoding='utf-8-sig')
데이터 정제 후 빈도수를 시각화하여 상위 10개 단어의 빈도수를 확인하는 작업을 하였습니다.
여기서의 문제점을 발견하였는데 같은 노래에 동일한 가사가 반복하는 경우 빈도수가 높게 나오는 것을 확인했습니다.

워드 클라우드 결과:
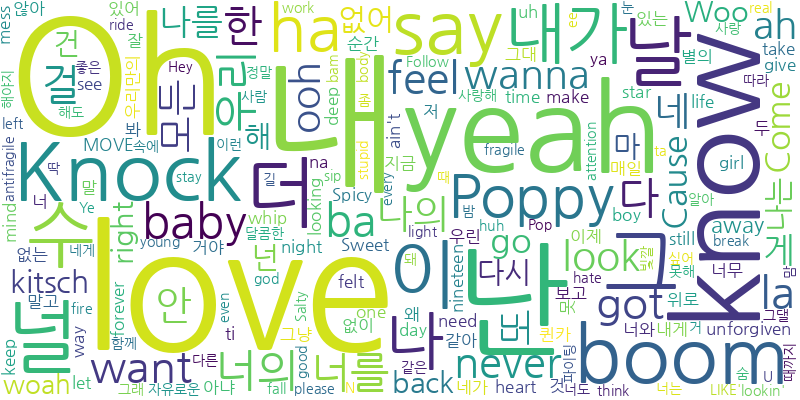
장르 분류
우선 장르 분류를 하기 위해서는 top100차트 외에 genre열이 필요한 훈련 데이터가 필요합니다. 아까와 마찬가지로 track_ids 배열에 직접 넣는 방식으로 top 100 발라드, 댄스/팝, 랩/힙합, 락/메탈, 알앤비/소울 총 5개의 데이터 셋을 만들었습니다.
# 발라드 훈련 데이터 만들기
import csv
import requests
from bs4 import BeautifulSoup
def get_lyrics(lyrics_url):
request = requests.get(lyrics_url)
html = request.content
soup = BeautifulSoup(html, 'html.parser')
lyrics_element = soup.find('xmp')
return lyrics.replace('\n', '')
# 곡의 아이디
track_ids = ['6196923','3387407','30994623','6201910','6110464','6201103','6197674','6202756','6197256','6131070',
'6176266','6140459','6158753','6202761','32558931','6167930','6141496','32735024','6198891','6203861',
'6203050','6154437','6203393','6195111','6201871','9009725','6204009','6197295','6197818','32845390',
'32542643','6203051','32655074','31517011','31708907','31009023','32737858','6191191','6203962','6179313',
'4679944','30810187','6203311','30598121','32519088','6017661','32872611','6187426','6140933','30713225',
'6184417','5661543','6198758','6138863','30269202','80270962','6183287','6202835','31655942','2746407',
'6203065','6162383','31703429','6139644','32270073','6199643','5251443','31290534','6202113','3455796',
'6138444','31833487','32333008','6202276','30141845','6204021','31540341','80284748','6127040','31833551',
'6188211','6189041','31740348','32518987','6178800','31527735','31673863','30694752','80076144','31746566',
'6168006','32478445','6097472','5956261','32333012','32301663','6171034','80204348','30725983','503339'] # Replace with your track IDs
# 차트 데이터
chart_data = []
for i, track_id in enumerate(track_ids):
# Modify the URL with the track ID
lyrics_url = 'https://music.bugs.co.kr/track/{}'.format(track_id)
lyrics = get_lyrics(lyrics_url)
chart_data.append([i+1, lyrics])
# csv 파일로 전환
filename = 'ballad_lyrics.csv'
with open(filename, 'w', newline='', encoding='utf-8-sig') as file:
writer = csv.writer(file)
writer.writerow(['Rank', 'Lyrics']) # Write header row
writer.writerows(chart_data) # Write chart data rows
print('{} 생성'.format(filename))
그렇게 만들어진 5개의 데이터 셋을 1개로 합쳐서 train_data에 저장하였습니다.
# 장르 분류
train_data = pd.read_csv('/content/sample_data/train_music_chart.csv',encoding='cp949')
data = pd.read_csv('/content/sample_data/music_chart_0623_1128.csv',encoding='cp949')
train_data.tail(10)
이후 아까와 같이 \r 문제가 발생하여 \r을 제거한 후 데이터를 다시 저장합니다.
# '\r' 제거
train_data['Lyrics'] = train_data['Lyrics'].str.replace('\r', '')
train_data.head(10)
마지막으로 훈련셋에서 Lyrics와 genre열을 추출한 뒤 Tf-idf Vectorizer를 이용하여 텍스트 데이터를 벡터화 해줍니다.
import pandas as pd
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.linear_model import LogisticRegression
# 훈련셋에서 'Lyrics'와 'genre' 열 추출
X_train = train_data['Lyrics']
y_train = train_data['genre']
# TfidfVectorizer를 사용하여 텍스트 데이터 벡터화
vectorizer = TfidfVectorizer()
X_train_vectorized = vectorizer.fit_transform(X_train)
# 로지스틱 회귀 모델 학습
model = LogisticRegression()
model.fit(X_train_vectorized, y_train)
# 원본셋에서 'Lyrics' 열 추출
X_data = data['Lyrics']
# 원본셋을 벡터화
X_data_vectorized = vectorizer.transform(X_data)
# 학습된 모델을 사용하여 장르 분류
predicted_genres = model.predict(X_data_vectorized)
# 예측된 장르를 원본셋에 추가
data['genre'] = predicted_genres
# 결과 출력
print(data)
# csv파일로 저장
data.to_csv('genre_predict_music_chart.csv',index=False, encoding='cp949')장르 분류 결과:
다음과 같이 분류가 제대로 되는 것을 확인할 수 있습니다.

가사를 준 뒤 장르 예측 모델
장르 예측까지 끝낸 뒤 사용자가 가사를 입력해서 가사를 분석해 장르를 예측하는 모델을 만들었습니다.
우선 이전까지 진행했던 장르 분류 결과를 csv파일로 저장한 뒤 불러옵니다.
train_data = pd.read_csv('/content/sample_data/genre_predict_music_chart.csv',encoding='cp949')
train_data.tail(10)
하지만 이 데이터 셋에는 문제점이 있었는데 바로 데이터셋이 너무 적다는 점이었습니다. 데이터갯수가 100개 밖에 되지않아 장르 예측도 잘 되지않고 모델로써의 기능도 제대로 수행하지 못할 거 같아 데이터를 추가하였습니다.
데이터를 더 추가하기 위해 top100 멜론 차트 데이터와 캐글에 존재하는 빌보드(1999~2010) 데이터를 추가하였습니다.
빌보드에 있는 데이터 중 Maroon5, 에미넴의 데이터를 각각 genre는 POP, rap_hiphop으로 정의하여 150개, 150개 추가하였습니다.
그렇게 모은 데이터 셋을 불용어 처리를 한 뒤 TfidfVectorizer를 통해 단어 빈도와 문서 빈도에 역수를 벡터화 시켜줍니다.
import pandas as pd
import re
from sklearn.feature_extraction.text import TfidfVectorizer
# 소문자 변환
train_data['Lyrics'] = train_data['Lyrics'].str.lower()
# 특수문자 제거
train_data['Lyrics'] = train_data['Lyrics'].apply(lambda x: re.sub('[^a-zA-Zㄱ-ㅣ가-힣0-9\s]', '', x))
# 불용어 처리 (예시)
stop_words = ['나', '너', '우리', '그', '이', '저', '있', '하', '것', '들', '및', '위해','I', 'me', 'my', 'myself', 'we', 'our', 'ours', 'ourselves', 'you', 'your', 'yours', 'yourself', 'yourselves',
'he', 'him', 'his', 'himself', 'she', 'her', 'hers', 'herself', 'it', 'its', 'itself', 'they', 'them', 'their',
'theirs', 'themselves', 'what', 'which', 'who', 'whom', 'this', 'that', 'these', 'those', 'am', 'is', 'are', 'was',
'were', 'be', 'been', 'being', 'have', 'has', 'had', 'having', 'do', 'does', 'did', 'doing', 'a', 'an', 'the',
'and', 'but', 'if', 'or', 'because', 'as', 'until', 'while', 'of', 'at', 'by', 'for', 'with', 'about', 'against',
'between', 'into', 'through', 'during', 'before', 'after', 'above', 'below', 'to', 'from', 'up', 'down', 'in',
'out', 'on', 'off', 'over', 'under', 'again', 'further', 'then', 'once', 'here', 'there', 'when', 'where', 'why',
'how', 'all', 'any', 'both', 'each', 'few', 'more', 'most', 'other', 'some', 'such', 'no', 'nor', 'not', 'only',
'own', 'same', 'so', 'than', 'too', 'very', 's', 't', 'can', 'will', 'just', 'don', 'should', 'now'] # 사용자 정의 불용어 사전
train_data['Lyrics'] = train_data['Lyrics'].apply(lambda x: ' '.join([word for word in x.split() if word not in stop_words]))
# TF-IDF 벡터화
vectorizer = TfidfVectorizer()
X_lyrics_vectorized = vectorizer.fit_transform(train_data['Lyrics'])
# 데이터 확인
print(X_lyrics_vectorized)
해당 사진은 print(X_lyrics_vectorized)의 결과입니다.

사진에 나온 결과는 (i, j) 즉 i번쨰 문서에서 단어 j에 대한 TF-IDF의 가중치를 표현한 것이며 그 옆 숫자는 가중치를 수치화 한것 입니다. 즉 (0,20993)는 0번째 문서에서 단어 209993번쨰에 대한 가중치 0.0537..(이하 생략) = 0.0537만큼 단어가 이 문서에서 중요하다는 뜻입니다.
이후 LogisticRegression과 classification_report 패키지를 불러와 회귀 분석과 그에 관한 report를 출력할 수 있게 패키지를 불러오고
X값으로는 가사, y값으로는 장르를 이용해 회귀 분석을 진행하였습니다.
한 가지 특이한점으로는 test_size를 기본값 0.2가 아닌 0.1로 진행하였는데 데이터를 추가했음에도 자체 데이터 수가 부족해 test셋의 비율을 줄였습니다.
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
# X =가사, y = 장르
X = train_data['Lyrics']
y = train_data['genre']
# TF-IDF
vectorizer = TfidfVectorizer()
X_vectorized = vectorizer.fit_transform(X)
# 학습 데이터와 테스트 데이터로 분할
X_train, X_test, y_train, y_test = train_test_split(X_vectorized, y, test_size=0.1, random_state=42)
# 로지스틱 회귀 모델 학습
model = LogisticRegression()
model.fit(X_train, y_train)
# 테스트 데이터로 예측 수행
y_pred = model.predict(X_test)
# 분류 보고서 출력
print(classification_report(y_test, y_pred))
분류 성능 평가의 결과는 다음과 같았습니다
POP, ballad, rap_hiphop의 장르 같은 경우는 f1-score는 높았던 반면 rnb_soul, rock_metal의 경우에는 데이터 수가 적어서 분류를 잘 못한다는 결과가 나왔습니다. 정확도는 72%로 조금 낮게 나왔는데 이 또한 데이터 수가 적어서라고 판단했습니다.

데이터 셋에 없는 가사를 집어 넣고 테스트를 해본 결과 ballad의 가사 분류는 잘 예측 되는것을 확인했습니다.
해당 가사는 플라이 투 더 스카이의 가슴 아파도의 하이라이트 부분을 일부 발췌했습니다.
해당 장르의 가사는 음악차트(멜론, 벅스, 지니뮤직 등)에서 발라드로 분류가 되어있습니다.
하지만 다른 장르의 가사를 집어 넣을 시에 예측을 못할 확률이 매우 높은 관계로 이에 대한 대책으로는 데이터 셋을 더 늘리고 장르를 좀 더 세분화 하는 방법이 있습니다.
# 가사를 입력받기
def predict_genre(lyrics):
lyrics_vectorized = vectorizer.transform([lyrics])
predicted_genre = model.predict(lyrics_vectorized)
return predicted_genre[0]
# 예측 함수
lyrics = "가슴 아파도 나 이렇게 웃어요"
predicted_genre = predict_genre(lyrics)
print(f"해당 장르는 {predicted_genre} 입니다.")
# 결과값
# 해당 장르는 ballad 입니다
느낀점 :
토이 프로젝트를 혼자 진행하면서 막히는 부분도 있었지만 여러 개발자들의 도움과 스택오버플로우 및 개발자 커뮤니티에 정보를 찾아가며 공부한 결과 제 코딩실력은 한층 더 늘게 되었고 이전에 실행했던 성심당 워드클라우드와는 또 다른 지식들을 많이 얻을 수 있어서 한층 성장할수 있는 계기가 되었습니다.
링크 :
https://music.bugs.co.kr/chart
나를 위한 플리, 벅스
나를 위한 플리, 벅스! 마음을 담은 노래추천 플레이리스트, 그리고 일상을 감성으로 가득 채워줄 essential player까지
music.bugs.co.kr
https://music.bugs.co.kr/genre/home
나를 위한 플리, 벅스
나를 위한 플리, 벅스! 마음을 담은 노래추천 플레이리스트, 그리고 일상을 감성으로 가득 채워줄 essential player까지
music.bugs.co.kr
'프로젝트' 카테고리의 다른 글
| Move(만보기앱)에 대한 데이터 셋 만들기 및 가공 (0) | 2023.06.07 |
|---|---|
| 카카오톡 대화 내용 워드클라우드 (0) | 2023.01.13 |
| 성심당 리뷰를 이용한 긍정, 부정 워드클라우드 프로젝트 (0) | 2022.12.24 |