728x90
목차
실습에 필요한 테이블 및 자료

DROP TABLE IF EXISTS mst_city_ip;
CREATE TABLE mst_city_ip(
network inet PRIMARY KEY
, geoname_id integer
, registered_country_geoname_id integer
, represented_country_geoname_id integer
, is_anonymous_proxy boolean
, is_satellite_provider boolean
, postal_code varchar(255)
, latitude numeric
, longitude numeric
, accuracy_radius integer);
DROP TABLE IF EXISTS mst_locations;
CREATE TABLE mst_locations(
geoname_id integer PRIMARY KEY
, locale_code varchar(255)
, continent_code varchar(10)
, continent_name varchar(255)
, country_iso_code varchar(10)
, country_name varchar(255)
, subdivision_1_iso_code varchar(10)
, subdivision_1_name varchar(255)
, subdivision_2_iso_code varchar(10)
, subdivision_2_name varchar(255)
, city_name varchar(255)
, metro_code integer
, time_zone varchar(255)
, is_in_european_union varchar(10)
);먼저 다운을 받기 전 데이터베이스 테이블을 만들어야 하므로 다음과 같은 쿼리를 입력해야한다 그 이유는 csv 파일을 테이블에 정의하고 데이터를 읽어들이기 위해서이다.
이후 해당 사이트에서 geolite2, 각 국가와 국가의 도시들의 데이터베이스가 담겨 있는 파일들을 다운받는다.
필요한 파일은 총 2개로 GeoLite2-City-Blocks-IPv4.csv, GeoLite2-City-Locations-en.csv이다.
IPv4는 해당 지역의 id값, 위도, 경도와 같은 지리적 정보를 담은 테이블이고 Locations-en의 경우는 국가 번호, 국가 코드, 국가의 이름 및 상세 지역의 이름과 코드의 정보들이 담겨져 있는 테이블이다.
GeoLite2는 맥스마인드라는 업체에서 제공하는 무료 지오로케이션 데이터베이스이다. 다양한 종류의 클라이언트에서 활용할 수 있는 이진 파일, csv 파일들을 제공한다.
https://dev.maxmind.com/geoip/geolite2-free-geolocation-data
GeoLite2 Free Geolocation Data
Develop applications using industry-leading IP intelligence and risk scoring.
dev.maxmind.com
IP 주소로 국가와 지역 정보 확인하기
- 해당 쿼리는 액션 로그의 IP 주소로 국가와 지역 정보를 추출하는 쿼리이다.
SELECT
a.ip
, l.continent_name
, l.country_name
, l.city_name
, l.time_zone
FROM
action_log_with_ip AS a
LEFT JOIN
mst_city_ip AS i
ON a.ip::inet << i.network
LEFT JOIN
mst_locations AS l
ON i.geoname_id = l.geoname_id;
주말과 공휴일 판단하기
- 일반적인 서비스는 주말과 공휴일에 방문 횟수 와 CV가 늘어난다. 주말과 공휴일이 얼마나 되는지 계산을 통해 더 정확한 목표 세울 수 있다.
- 해당 쿼리는 주말과 공휴일 정의하는 쿼리이다.
CREATE TABLE mst_calendar(
year integer
, month integer
, day integer
, dow varchar(10)
, dow_num integer
, holiday_name varchar(255));- 주말과 공유일을 판정하는 쿼리
SELECT
a.action
, a.stamp
, c.dow
, c.holiday_name
-- 주말과 공휴일 판정
, c.dow_num IN(0,6) OR c.holiday_name IS NOT NULL AS is_day_off
FROM
access_log AS a
JOIN
mst_calendar AS c
ON CAST(substring(a.stamp, 1, 4) AS int) = c.year
ON CAST(substring(a.stamp, 6, 2) AS int) = c.month
ON CAST(substring(a.stamp, 9, 2) AS int) = c.day
이상값 검출하기
- 데이터 분석 진행 할 때는 데이터의 정합성 보장을 전제로 한다.
- 보통 데이터는 노이즈가 낀 경우가 많아 데이터 정합성이 매우 떨어지게 된다.
- 이러한 노이즈 낀 데이터를 데이터 클렌징을 통해 웹사이트 접근 로그 기반으로 노이즈 등 이상값 검출 하는게 매우 중요한 작업이다.
- 이상값 검출하는 기본 방법으로는 데이터 분산을 계산하고 분산에서 벗어난 값 찾는 것이다.
- 다음 쿼리는 세션별로 페이지 열람 수 랭킹 비율 구하는 방법이다.
- 조회 수가 극단적으로 많은 경우, 세션별로 조회 수 계산 후 상위 n% 데이터를 확인한다.
WITH
session_count AS (
SELECT
session
, COUNT(1) AS count
FROM
action_log_with_noise
GROUP BY
session
)
SELECT
session
, count
, RANK() OVER(ORDER BY count DESC) AS rank
, PERCENT_RANK() OVER(ORDER BY count DESC) AS percent_rank
FROM
session_count;- URL 접근 수가 가장 낮은 비율 랭킹 비율 구하기
- 접근 수가 적은 URL을 상위에 출력해야 하므로 ASC로 정렬
WITH
url_count AS (
SELECT
url
, COUNT(*) AS count
FROM
action_log_with_noise
GROUP BY
url
)
SELECT
url
, count
, RANK() OVER(ORDER BY count ASC) AS rank
, PERCENT_RANK() OVER(ORDER BY count ASC)
FROM
url_count;크롤러 봇 판단하기
- 접근 로그에는 사용자 행동 이외에 검색 엔진, 크롤러가 접근한 로그가 섞인다.
- 사용자의 접근 수 만큼이나 그 이상 크롤러부터 접근이 발생하는 경우도 많다.
- 데이터 분석 시 크롤러 로그는 제거한 뒤 분석해야 하고 크롤러인지 사용자인지 판별하려면 사용자 에이전트 등을 보고 구분한다.
- 크롤러 접근 제외 방법
- 규칙 기반 제외
- 사용자 에이전트의 특징을 이용한다.
- 특정 문자열 : bot, crawler, spider..
- 이름 포함 : Googlebot, Baiduspider, Yeti…
- 규칙 기반 제외
SELECT *
FROM
action_log_with_noise
WHERE
NOT
-- 크롤러 판정 조건
( user_agent LIKE '%bot%'
OR user_agent LIKE '%crawler'
OR user_agent LIKE '%spider'
OR user_agent LIKE '%archiver'
);- 마스터 데이터를 사용해 제외하는 쿼리
- 이전 코드처럼 규칙 사용시, SQL에 직접 규칙을 작성하므로 SQL이 길어지게 되어 관리가 번거로울 수 있다.
- 따라서, 별도의 크롤러 마스터 데이터를 만들면 좀 더 편리하게 이용할 수 있다.
WITH
mst_bot_user_agent AS (
SELECT '%bot%' AS rule
UNION ALL SELECT '%crawler%' AS rule
UNION ALL SELECT '%spider%' AS rule
UNION ALL SELECT '%archiver%' AS rule
)
, filtered_action_log AS (
SELECT
l.stamp, l.session, l.action, l.products, l.url, l.ip, l.user_agent
-- WHERE 구문 상관 서브쿼리 O
FROM
action_log_with_noise AS l
WHERE
NOT EXISTS ( SELECT l
FROM mst_bot_user_agent AS m
WHERE l.user_agent LIKE m.rule)
)
SELECT *
FROM
filtered_action_log;
데이터 타당성 확인하기
- 분석 전 액션 로그 데이터의 타당성을 확인해야 하는 과정이 필요하다.
- Ex.) 액션(action)들은 GROUP BY로 집약, 액션 또는 사용자 ID 등의 각 컬럼이 만족해야 하는 조건을 CASE 식으로 판정 한뒤 조건을 만족하면 1, 아닐 경우 0으로 판단한다.
- 이후 CASE 식의 값을 AVG 함수로 집약해서 로그 데이터 전체의 조건 만족 비율을 계산한다.
SELECT
action
, AVG(CASE WHEN session IS NOT NULL THEN 1.0 ELSE 0.0 END) AS session
, AVG(CASE WHEN user_id IS NOT NULL THEN 1.0 ELSE 0.0 END) AS user_id
-- category는 action=view의 경우 NULL, 이외의 경우 NULL
, AVG(
CASE action
WHEN 'view' THEN
CASE WHEN category IS NULL THEN 1.0 ELSE 0.0 END
ELSE
CASE WHEN category IS NOT NULL THEN 1.0 ELSE 0.0 END
END
) AS category
-- products는 action=view의 경우 NULL, 이외의 경우 NULL
, AVG(
CASE action
WHEN 'view' THEN
CASE WHEN products IS NULL THEN 1.0 ELSE 0.0 END
ELSE
CASE WHEN products IS NOT NULL THEN 1.0 ELSE 0.0 END
END
) AS products
-- products는 action=view의 경우 NULL, 이외의 경우 NULL
, AVG(
CASE action
WHEN 'purchase' THEN
CASE WHEN amount IS NOT NULL THEN 1.0 ELSE 0.0 END
ELSE
CASE WHEN amount IS NULL THEN 1.0 ELSE 0.0 END
END
) AS amount
-- stamp는 반드시 NULL이 아니어야 함
, AVG(CASE WHEN stamp IS NOT NULL THEN 1.0 ELSE 0.0 END) AS stamp
FROM
invalid_action_log
GROUP BY
action;
데이터 중복 검출하기
- RDB는 적절하게 유니크 키를 설정했을 경우, 키가 중복되면 자동으로 오류가 발생하여 데이터 무결성 보장된다.
- 키가 중복되는 데이터의 존재 확인하기의 예시
- 데이터 로드 시 실수로 여러 번 로드되어 레코드 중복 생성된 경우
- 마스터 데이터 값 갱신 시 문제 발생하여, 데이터가 서로 다른 레코드로 분리된 경우
- 운용상 실수로 데이터 재사용한 경우
- 다음은 키의 중복을 확인하는 쿼리이다.
SELECT
COUNT(1) AS total_num
, COUNT(DISTINCT id) AS key_num
FROM
mst_categories;- 키가 중복되는 레코드 확인하기
SELECT
id
, COUNT(*) AS record_num
-- 데이터를 배열로 집약하고, 쉼표로 구분된 문자열로 변환하기
, string_agg(name, ',') AS name_list
, string_agg(stamp, ',') AS stamp_list
FROM
mst_categories
GROUP BY
id
HAVING COUNT(*) > 1 -- 중복된 ID 확인- 로그 중복 검출하기
- 사용자와 상품의 조합에 대한 중복을 확인하는 쿼리
SELECT
user_id
, products
, string_agg(session, ',') AS session_list
, string_agg(stamp, ',') AS stamp_list
FROM
dup_action_log
GROUP BY
user_id, products
HAVING
COUNT(*) > 1;- ROW_NUMBER를 사용해 중복을 배제하는 쿼리
WITH
dup_action_log_with_order_num AS (
SELECT
*
--중복된 데이터에 순번 붙이기
, ROW_NUMBER()
OVER(PARTITION BY session, user_id, action, products
ORDER BY stamp) AS order_num
FROM
dup_action_log
)
SELECT
session
, user_id
, action
, products
, stamp
FROM
dup_action_log_with_order_num
WHERE
order_num = 1;- 이전 액션으로부터의 경과 시간 계산 쿼리
WITH
dup_action_log_with_lag_seconds AS (
SELECT
user_id
, action
, products
, stamp
-- 같은 사용자와 상품 조합에 대한 이전 액션으로부터 경과 시간 계산
, EXTRACT(epoch from stamp::timestamp - LAG(stamp::timestamp)
OVER(PARTITION BY user_id, action, products
ORDER BY stamp)) AS lag_seconds
FROM
dup_action_log
)
SELECT
*
FROM
dup_action_log_with_lag_seconds
ORDER BY
stamp;여러 개의 데이터셋 비교하기
- 집계 작업에서는 여러 개의 데이터셋을 비교해서 어떤 판단을 내리는 경우가 많다.
- 데이터의 차이를 추출하는 경우 대량의 마스터 데이터에서는 육안으로 확인하기 힘들다(Ex.) 지역 합병 정책으로 우편 번호가 대량으로 바뀌는 경우)
- 데이터의 순위를 비교하는 경우 집계 기간 또는 출력 조건 변경 시 과거 로직과 비교해서 어떤 차이가 있었는지 등을 확실하게 해야 한다. 즉, 새로운 로직과 과거의 로직 변화를 정량적으로 설명할 수 있어야 한다.
- 추가된 마스터 데이터 추출하기
- 두 개의 마스터 테이블에서 한쪽에만 존재하는 레코드 추출 시 OUTER JOIN 사용
- 다음 코드처럼 새로운 마스터 테이블에만 존재하는 레코드 추출 시 새로운 테이블 기준으로 오래된 테이블을 LEFT OUTER JOIN, 오래된 테이블 컬럼이 NULL인 레코드를 추출하면 된다.
SELECT
new_mst.*
FROM
mst_products_20170101 AS new_mst
LEFT OUTER JOIN
mst_products_20161201 AS old_mst
ON
new_mst.product_id = old_mst.product_id
WHERE
old_mst.product_id IS NULL;- 제거된 마스터 데이터 추출하기
SELECT
old_mst.*
FROM
mst_products_20170101 AS new_mst
RIGHT OUTER JOIN
mst_products_20161201 AS old_mst
ON
new_mst.product_id = old_mst.product_id
WHERE
new_mst.product_id IS NULL;- 갱신된 마스터 데이터 추출하기
SELECT
new_mst.product_id
, old_mst.name AS old_name
, old_mst.price AS old_price
, new_mst.name AS new_name
, new_mst.price AS new_price
, new_mst.updated_at
FROM
mst_products_20170101 AS new_mst
JOIN
mst_products_20161201 AS old_mst
ON
new_mst.product_id = old_mst.product_id
WHERE
-- 갱신 시점이 다른 레코드 추출
new_mst.updated_at <> old_mst.updated_at;- 데이터 순위를 비교하는 경우
- 두 순위의 유사도 계산하기 : 지표들의 순위 작성
- 유사도를 계산하여 어떤 순위가 효율적인지 순위를 정량적으로 평가하는 방법
WITH
path_stat AS (
-- 경로별 방문 횟수, 방문자 수, 페이지 뷰 계산하기
SELECT
path
, COUNT(DISTINCT long_session) AS access_users
, COUNT(DISTINCT short_session) AS access_count
, COUNT(*) AS page_view
FROM
access_log
GROUP BY
path
)
, path_ranking AS(
-- 방문 횟수, 방문자 수, 페이지 뷰 순위 붙이기
SELECT 'access_user' AS type, path, RANK() OVER(ORDER BY access_users DESC) AS rank
FROM path_stat
UNION ALL
SELECT 'access_count' AS type, path, RANK() OVER(ORDER BY access_count DESC) AS rank
FROM path_stat
UNION ALL
SELECT 'page_view' AS type, path, RANK() OVER(ORDER BY page_view DESC) AS rank
FROM path_stat
)
SELECT *
FROM
path_ranking
ORDER BY
type, rank;- 경로별 순위들의 차이 계산하기
WITH
path_stat AS (
-- 경로별 방문 횟수, 방문자 수, 페이지 뷰 계산하기
SELECT
path
, COUNT(DISTINCT long_session) AS access_users
, COUNT(DISTINCT short_session) AS access_count
, COUNT(*) AS page_view
FROM
access_log
GROUP BY
path
)
, path_ranking AS(
-- 방문 횟수, 방문자 수, 페이지 뷰 순위 붙이기
SELECT 'access_user' AS type, path, RANK() OVER(ORDER BY access_users DESC) AS rank
FROM path_stat
UNION ALL
SELECT 'access_count' AS type, path, RANK() OVER(ORDER BY access_count DESC) AS rank
FROM path_stat
UNION ALL
SELECT 'page_view' AS type, path, RANK() OVER(ORDER BY page_view DESC) AS rank
FROM path_stat
)
, pair_ranking AS (
SELECT
r1.path
, r1.type AS type1
, r1.rank AS rank1
, r2.type AS type2
, r2.rank AS rank2
-- 순위 차이 계산하기, POWER로 제곱해서 계산
, POWER(r1.rank - r2.rank, 2) AS diff
FROM
path_ranking AS r1
JOIN
path_ranking AS r2
ON r1.path = r2.path
)
SELECT
*
FROM
pair_ranking
ORDER BY
type1, type2, rank1;- 스피어만 상관계수 구하기
- 순위 전체의 유사도는 스피어만 상관계수를 통해 계산할 수 있다.
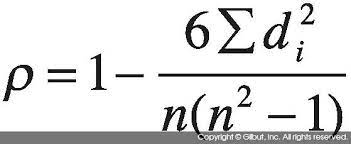
- 스피어만 상관계수를 통해 순위 유사도를 계산하는 쿼리
WITH
path_stat AS (
-- 경로별 방문 횟수, 방문자 수, 페이지 뷰 계산하기
SELECT
path
, COUNT(DISTINCT long_session) AS access_users
, COUNT(DISTINCT short_session) AS access_count
, COUNT(*) AS page_view
FROM
access_log
GROUP BY
path
)
, path_ranking AS(
-- 방문 횟수, 방문자 수, 페이지 뷰 순위 붙이기
SELECT 'access_user' AS type, path, RANK() OVER(ORDER BY access_users DESC) AS rank
FROM path_stat
UNION ALL
SELECT 'access_count' AS type, path, RANK() OVER(ORDER BY access_count DESC) AS rank
FROM path_stat
UNION ALL
SELECT 'page_view' AS type, path, RANK() OVER(ORDER BY page_view DESC) AS rank
FROM path_stat
)
, pair_ranking AS (
SELECT
r1.path
, r1.type AS type1
, r1.rank AS rank1
, r2.type AS type2
, r2.rank AS rank2
-- 순위 차이 계산하기, POWER로 제곱해서 계산
, POWER(r1.rank - r2.rank, 2) AS diff
FROM
path_ranking AS r1
JOIN
path_ranking AS r2
ON r1.path = r2.path
)
SELECT
type1
, type2
, 1 - (6.0 * SUM(diff) / (POWER(COUNT(1),3) - COUNT(1))) AS spearman
FROM
pair_ranking
GROUP BY
type1, type2
ORDER BY
type1, spearman DESC;'데이터분석 > PostgreSQL' 카테고리의 다른 글
| 데이터를 무기로 삼기 위한 분석 기술 (0) | 2023.07.30 |
|---|---|
| 웹사이트에서의 행동을 파악하는 데이터 추출하기 (0) | 2023.07.17 |
| 사용자를 파악하기 위한 데이터 추출 - 2 (2) | 2023.07.05 |
| 사용자를 파악하기 위한 데이터 추출 - 1 (0) | 2023.07.05 |
| 시계열 기반으로 데이터 집계하기 (0) | 2023.07.04 |