석사 과정중 1학기에 LLM, topic modeling쪽 연구를 진행하다 보니 관심이 많아 다른 topic modeling 논문들을 쭉 찾아보아았다. 그 중에 prompt를 이용하여 topic modeling을 제안한 논문이 있어 읽어보았다.
기존 topic modeling기법들의 한계
- 단어 집합이 bag of words로 표현되고 이런 집합들은 서로 관련이 없는 경우가 있음
- topic 생성시 중복된 단어가 포함된 경우가 많고 presentation이 명확하지 않음
- 특정 도메인에 맞지 않는 경우가 있음(domain에 특화된 embedding model이 필요함
하지만 본 논문에서 제안하는 TopicGPT의 contribution은 다음과 같다.
- 기존 topic modeling에서 해결하지 못했던 text data의 semantic을 탐색하기 위함
- 기존 방법이 제공하는 "bag of words" 기반 주제 표현 대신, LLM을 이용해 prompt를 통한 human-centric approach한 기법을 제안함
- 문서가 주어지면 LLM은 생성된 topic 중 한 개 이상에 해당 문서를 할당하고 인용문도 같이 제공함(기존의 방법을 타파함)
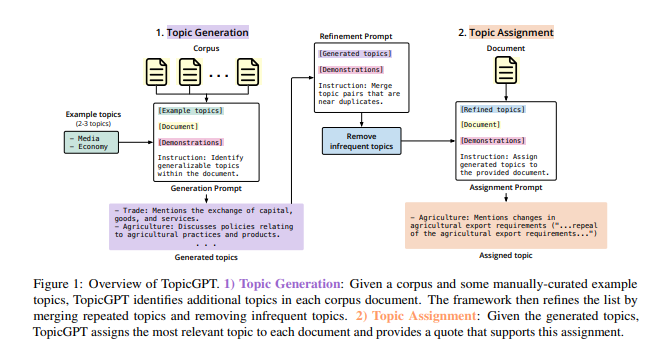
Framework
topicGPT의 구조는 다음 Figure 1에 나타나있는것과 같다.
1. Topic Generation
- sample document와 sample topic을 LLM에 제공하여 새로운 topic을 만들도록 prompt를 작성함
2. Refinement Prompt
- 생성된 topic에서 중복되거나 빈도 수가 낮은 주제는 제거함(cosine similarity를 계산하여 0.5보다 낮은 주제는 제거)
3. Topic Assignment
- LLM에 생성된 topic 목록과 문서를 제공하고, 가장 적합한 주제를 선택하도록 함
- LLM의 반환 정보

- label(topic 이름)
- topic description(topic에 대한 설명)
- quote(인용문)
4. Self correction
- 낮은 quality나 formatting이 잘못된 경우, self correction 단계를 거쳐 유효한지 확인한다.(e.g. None/Error 인지 판단하고 다시 적합한 주제를 재할당)
Dataset
Wikipedia
- 14,290개의 Wikipedia 문서로 구성함
- 총 15개의 high-level labels, 45개의 mid-level labels, 279개의 low-level human-annotated labels로 이루어짐
Congression Bills
- 32,661개의 법안 요약들로 구성됨
- 21개의 high-level labels, 114개의 low-level lables human-annotated labels로 이루어짐
baseline method : 기존에 많이 사용된 topic modeling(LDA, BERTopic, SeededLDA)이랑 비교함
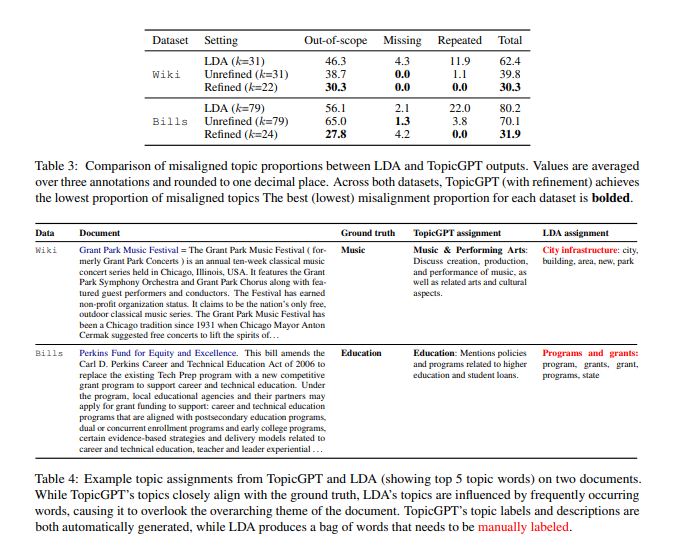
Experiment Result

Evaluation metric으로 topical alignment와 stability를 사용함
topical alignment은 데이터와 얼마나 일치하는지 측정하기 위해 다른 클러스터링 지표를 사용함
- Purity : 주어진 클러스터가 얼마나 well하게 정렬되었는지를 나타냄
- Adjusted Rand Index(ARI) : 예측 클러스터와 실제 클러스터 간의 pairwise를 측정함
- Normalized Mutual Information(NMI) : 예측한 클러스터와 실제 클러스터 간의 공유 정보를 나타냄
Limitations
- 비공개된 모델의 투명성 문제
- GPT-4, GPT-3.5를 사용하여 해당 LLM에 대한 model framework, parameter, tuning process등이 부족함
- 비용 문제
- TopicGPT의 GPT-3.5, 4의 API 사용에 따른 cost가 발생함
- 다른 오픈소스 모델을 사용하여 이를 해결해야함
- 문맥 길이 제한 문제
- Prompt에 대한 limitation이 존재하고 이로 인해 내용 전체를 정확하게 반영하기는 힘듬(token수 제한)
- future works로 문서를 부분적으로 나누어 순차 입력하는 것과 요약본을 제공하는 등을 진행하고 있음