UST 인턴 중 두번째 과제로 nrf2 데이터를 이용해 binary classification을 진행하였다.
이 classification을 통해 정말 이 약물로 실험을 진행한 결과가 정확한지에 대해서 판단하는 것이었고 roc curve, accuracy, classification report같은 지표를 활용해 검증하는 작업이었다.
💡nrf2란?
nrf2 (Nuclear Factor Erythroid 2-Related Factor 2)는 인간을 포함한 여러 생물에서 발견되는 중요한 전사 조절 인자이다. NRF2는 주로 세포의 항산화 반응 및 세포 보호 메커니즘을 조절하는 역할을 한다. 이 단백질은 세포가 다양한 스트레스 요인, 예를 들어 산화적 스트레스, 독성 물질, 중금속과 같은 환경적 도전에 직면했을 때 활성화된다.
데이터 수집 단계
우선, nrf2 데이터를 구하기 위해 화학 약물 데이터베이스 사이트인 ChEMBL 접속을 했다.
ChEMBL링크:
ChEMBL Database
A manually curated database of bioactive molecules with drug-like properties
www.ebi.ac.uk
접속한 뒤 nrf2를 검색한 뒤 targets -> compounds를 오름차순으로 정렬하면 다음과 같이 나오게 된다.

해당 데이터를 클릭하면 다음과 같은 페이지로 이동하며 csv파일로도 다운받을 수 있다.
데이터가 어느정도 좀 있는지라 다운 받는데 시간이 좀 걸리며 사이트 네트워크 문제로 다운이 잘 받아지지 않을 때가 있었다(본인의 경우 6번 정도 시도하여 겨우 받음)

다운 받은 뒤 csv파일을 열어보면 데이터가 열마다 구분되어 있지 않고 구분자가 ;로 되어있어서 바로 데이터 분석을 하기엔 어려웠다.
rawdata의 구분자를 없애기 위해 사전적으로 전처리 과정을 진행했다.
구분자 뿐만 아니라 전처리 과정 중 데이터 안에 들어 있는 금속 원소를 제거, 중복 데이터, pIC50 값 열을 생성하기 위해 이 과정을 진행하였다.
pIC50값을 위한 계산식은 다음과 같다(워낙 많으므로 일부만 써놓았다)

# 전처리 과정
df['pIC50'] = -np.log10(df['Standard Value'])
#Check duplicated structure.
df_dup = df[df.duplicated(subset='Smiles',keep=False)]
print ('The number of duplicated molecules:', df_dup.shape)
df_single = df[~df.duplicated(subset='Smiles',keep=False)]
print ('The number of single molecule:', df_single.shape)
#Calculate mean, max, min value of pIC50
mean_pIC50 = -np.log10(temp_df['Standard Value'].mean())
max_pIC50 = temp_df['pIC50'].max()
min_pIC50 = temp_df['pIC50'].min()
dif_mean_max = abs(max_pIC50 - mean_pIC50)
dif_mean_min = abs(mean_pIC50 - min_pIC50)
if max(dif_mean_max, dif_mean_min) < 0.5:
#Get the IC50 mean value.
temp_df['pIC50']=mean_pIC50
#Collect dataframe.
df_list.append(temp_df.iloc[0])
사전 전처리 과정 이후 구분자가 사라졌고 깔끔하게 해당 열 마다 데이터 제대로 들어간 모습을 확인할 수 있었다.

EDA 단계
첫번째로 데이터를 정상적으로 불러와지는지 확인했고 데이터의 특성 및 분포를 파악하기 위해 EDA를 진행하였다.
nrf2_data = pd.read_csv('nrf2_data.csv')
nrf2_data.head(5)
nrf2_data.info()
총 49개의 열이 있고 그 중에 내가 분석에 사용할 열은 target : pIC50과 feature : Smiles 열이 필요했다.
추가로 데이터 분포 및 특성을 확인하기 위해 AlogP, Comment, Molecular Weight열도 필요했고 나머지 열들은 dropna를 사용하여 모두 제거했다.
결측치 확인까지 진행하였는데 결측치가 존재했지만 교수님께서 결측치도 필요하다고 하셔서 따로 제거하지 않았다.
# 필요없는 열 제거
columns_to_drop = [col for col in nrf2_data.columns if col not in ['Smiles', 'Molecular Weight', 'AlogP','pIC50', 'Comment']]
nrf2_data_clean = nrf2_data.drop(columns=columns_to_drop)
# csv로 저장
nrf2_data_clean.to_csv('nrf2_data_clean.csv',index=False)
# 결측치 확인
nrf2_data.isnull().sum()
이후 train, test셋으로 나누어 분포도를 확인하였다.
# 분포 확인 및 train, test 나누기
train_data, test_data = train_test_split(nrf2_data, test_size=0.2, random_state=42)
# train, test 결합
combined_data = pd.concat([train_data, test_data])
## 산점도(train vs test)
plt.figure(figsize=(10, 6))
plt.scatter(train_data['Molecular Weight'], train_data['AlogP'], color='b', marker='o', alpha=0.7, label='Training Set')
plt.scatter(test_data['Molecular Weight'], test_data['AlogP'], color='r', marker='o', alpha=0.7, label='Testing Set')
plt.title('Scatter Plot of Molecular Weight vs. LogP (Combined Set)')
plt.xlabel('Molecular Weight')
plt.ylabel('LogP')
plt.legend()
plt.show()
## 히스토그램(train vs test)
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(15, 6))
# Training Set
ax1.hist(train_data['pIC50'], bins=50, color='b', alpha=0.7, label='Training Set')
ax1.set_title('Histogram of pIC50 (Training Set)')
ax1.set_xlabel('pIC50')
ax1.set_ylabel('Frequency')
ax1.legend()
# Testing Set
ax2.hist(test_data['pIC50'], bins=50, color='r', alpha=0.7, label='Testing Set')
ax2.set_title('Histogram of pIC50 (Testing Set)')
ax2.set_xlabel('pIC50')
ax2.set_ylabel('Frequency')
ax2.legend()
# 그래프 출력
plt.tight_layout()
plt.show()

다음과 같이 분포를 확인할 수 있었는데 scatterplot의 경우 train, test가 잘 겹치게 나타나있는걸 확인했지만 히스토그램의 경우 정규분포가 아닌 skewed-right distribution이 나오게 되었다.
히스토그램을 살펴보면 중복데이터가 좀 많은 거 같았고 특정 값이 너무 높게 나오는 이상치가 존재하였기에 이를 다 제거하는 작업을 진행하였다.
# 중복값 확인
train_unique = train_data['pIC50'].unique()
test_unique = test_data['pIC50'].unique()
# 중복값 갯수
train_value_count = train_data['pIC50'].value_counts()
test_value_count = test_data['pIC50'].value_counts()
# 중복값 상위 10개
train_value_count.head(10)
#test_value_count.head(10)
확인해보니 중복값이 많다는 것을 확인할 수 있었다. 이는 다른 smiles식을 가져도 똑같은 값이 많이 나오는 것을 보아 실험이 실패한 값이라고 교수님께서 설명해주셨다.
이후 이 중복값들을 제거하고 다시 분포를 살펴보았다.
# 중복 제거 후 값
train_data_dedup = train_data.drop_duplicates(subset='pIC50')
test_data_dedup = test_data.drop_duplicates(subset='pIC50')
# Plotting the histograms
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(15, 6))
# Training Set without duplicates
ax1.hist(train_data_dedup['pIC50'], bins=200, color='b', alpha=0.7, label='Training Set (No Duplicates)')
ax1.set_title('Histogram of pIC50 (Training Set, deduplicate)')
ax1.set_xlabel('pIC50')
ax1.set_ylabel('Frequency')
ax1.legend()
# Testing Set without duplicates
ax2.hist(test_data_dedup['pIC50'], bins=200, color='r', alpha=0.7, label='Testing Set (No Duplicates)')
ax2.set_title('Histogram of pIC50 (Testing Set, deduplicate)')
ax2.set_xlabel('pIC50')
ax2.set_ylabel('Frequency')
ax2.legend()
plt.tight_layout()
plt.show()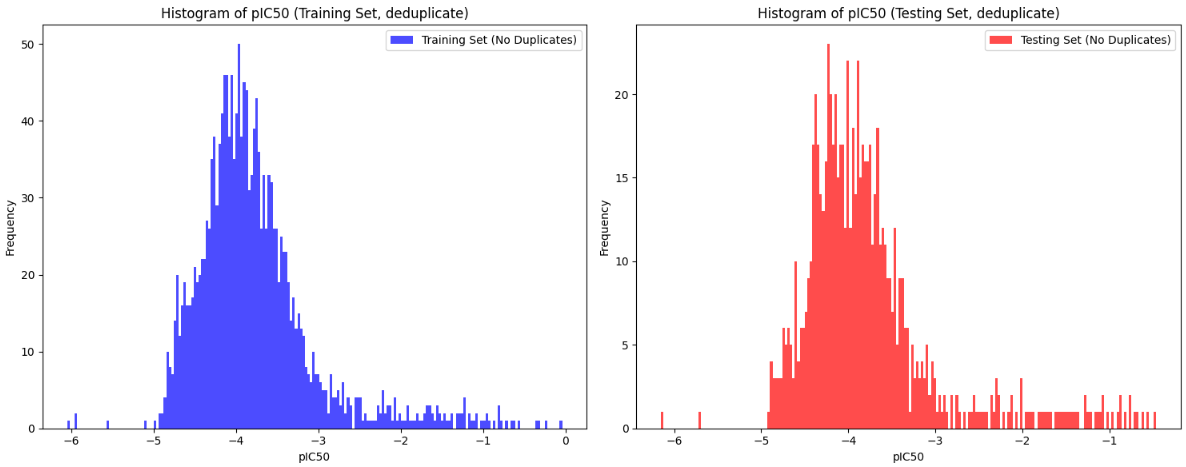
제거하고 나니 다음과 같은 정규분포 형태의 그래프가 나오는 것을 확인할 수 있었다.
교수님께서 추가적으로 봐야 할 사항으로 Comment열에 주목하라고 하셨다.
Comment열에는 inactive, active, inconclusive 3가지가 있었으며 이 값에 따른 분포도 확인하라고 하셨다.
# Comment 값에 따른 변수
data_inactive = data[data['Comment'] == 'inactive']
data_active = data[data['Comment'].str.lower() == 'active']
data_inconclusive = data[data['Comment'] == 'inconclusive']
# "inactive"
plt.hist(data_inactive['pIC50'], bins=100, color='r', alpha=0.7, label='Data Set (inactive)')
plt.title('Comment : inactive')
plt.xlabel('pIC50')
plt.ylabel('Frequency')
plt.legend()
plt.show()
# "active"
plt.hist(data_active['pIC50'], bins=100, color='b', alpha=0.7, label='Data Set (active)')
plt.title('Comment : active')
plt.xlabel('pIC50')
plt.ylabel('Frequency')
plt.legend()
plt.show()
# "inconclusive"
plt.hist(data_inconclusive['pIC50'], bins=100, color='g', alpha=0.7, label='Data Set (inconclusive)')
plt.title('Comment : inconclusive')
plt.xlabel('pIC50')
plt.ylabel('Frequency')
plt.legend()
plt.show()


💡inconclusive data?
데이터 분석 또는 실험에서 어떤 결론을 도출하기 어려운 또는 명확한 결론을 내릴 수 없는 데이터를 나타내는 용어이다. 이는 주어진 데이터의 특성, 노이즈, 불확실성 등으로 인해 정확한 결론을 내릴 수 없는 경우를 말한다.
분포도를 확인할 결과 전체 약 83000개의 데이터 중 inconclusive의 데이터가 75355개로 상당수를 차지하는 것을 볼 수 있었다. 그래서 classification accuracy에 inconclusive의 데이터가 영향을 미치는지 안 미치는지 궁금해서 inconclusive를 뺴고도 진행을 하면 어떨까 라는 생각이 들었다.
data['Comment'].value_counts()

'2024 동계 UST 인턴' 카테고리의 다른 글
| [UST] 분자 구조 예측 모델 만들기 - 2 (0) | 2024.02.02 |
|---|---|
| [UST] 분자 구조 예측 모델 만들기 - 1 (0) | 2024.02.02 |
| [UST] nrf2 classification - 3 (0) | 2024.01.29 |
| [UST] nrf2 classification - 2 (1) | 2024.01.26 |
| 안전성평가연구소에서 인턴십 시작 (0) | 2024.01.12 |